Locality-sensitive hashing for angular distance in Python
With the advent of deep learning more and more of our data is represented as vectors of numbers. Words, images, whole sentences - all can be encoded this way. Finding similar items in big sets of vectors efficiently very common problem.
Locality-sensitive hashing (LSH) is an important group of techniques which can be used to speed up vastly the task of finding similar sets or vectors. The general idea is to hash each item using a group of functions, which have the property that the hashes are more likely to be equal if the items are similar. This way we can group the items into buckets and compare only inside those.
Similarity of items
What does it mean that items are similar? We usually think of vectors as similar if the distance between them is sufficiently small. Going further we can think of distance as a function which takes a pair of vectors and returns a real number. A distance measure (metric) has a mathematical meaning, which you can look up here. The typical example of metric is an Euclidean distance which you could’ve heard about in school. In this post however we will use the angular distance - a measure closely related to Cosine similarity, which is often used with embedding vectors.
We can compute cosine similarity as follows:
def cosine_similarity(a, b):
return np.dot(a, b) / (np.sqrt(np.dot(a, a)) * np.sqrt(np.dot(b, b)))
Now to get angular distance we need to transform the cosine value to an angle and normalize so that it’s range is [0, 1]:
def angular_distance(a, b):
return np.arccos(cosine_similarity(a, b)) / np.pi
LSH and random hyperplanes
Let’s imagine two vectors in n-dimensional space x and y, with an angle between them θ. They will define the hyperplane H displayed in the following figure:
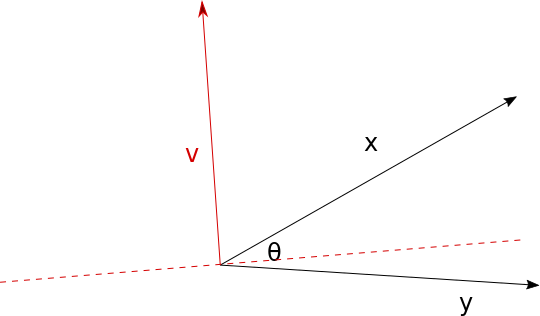
Now let’s say we have a random vector v normal to the hyperplane G which intersection with H is depicted as dashed red line. If the H is between x and y the vector products: vx and vy will have different signs. The probability of getting vector v like this is proportional to the angle θ, so is the probability of vx and vy having different signs. Otherwise vector products signs will be the same.
This observation leads to the following hashing procedure. Suppose we want to hash set of vectors X. Let’s draw k n-dimensional random vectors. Now let’s compute the dot products of these random vectors with each vector in X and let’s store only the information about the product sign - 1 for positive and 0 for negative sign. This way we’ll obtain a set of k-dimensional binary vectors (called sketches) for each vector in X. Now if we want to approximate the angle between any of the vectors from the set we take their hash encoding and compute the ratio (r) of agreeing positions to all positions. The (1 - r) x 180 is our approximation. More random vectors we use closer our approximation will be which follows from the Law of large numbers. Next figure shows scatter plots of angular distance between a 10-dimensional vector and other 999 vectors compared to the ratio of equal positions in their sketches.
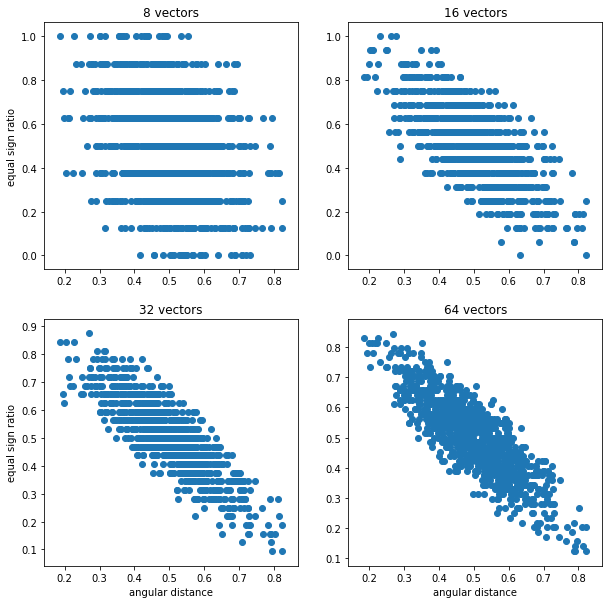
As you can see more vectors we use the better is correlation between angular distance and the ratio. Other important note is that more vectors we use smaller is the possible distance which will make close but not equal vectors fall into the same bucket. In this example it was more than 10 for 8 vectors, only 3 for 16 vectors, and none for 32 and 64 vectors.
The probability of hashing two vectors to the same bucket, if their distance is θ equals to:
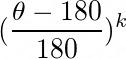
Toy index implementation
Now as we have some basic knowledge let’s take a look at a simple index implementation:
class AngularLSHIndex(object):
def __init__(self, dim, hash_no):
# dim - dimensionality of used vectors
self.dim = dim
self.hash_no = hash_no
# draw hash_no random vectors
self.hash_vecs = np.random.uniform(low=-1.0, size=(hash_no, dim))
# standard python dictionary will be our "index"
# for small hash_no values this could be a list
self.db = {}
def get_hash_key(self, vec):
# compute dot product of all hash vectors
# and check the sign
sv = vec.dot(self.hash_vecs.T) > 0
# binary vector to byte string
return np.packbits(sv).tostring()
def add(self, vec):
k = self.get_hash_key(vec)
self.db.setdefault(k, []).append(vec)
def get(self, vec):
k = self.get_hash_key(vec)
return self.db.get(k, [])
Using sketches as “hash vectors”
We can use binary vectors instead of float vectors in our hash function. Then instead of using the sign of a dot product we’ll use the sign of the dot_binary method result to compute the hashes.
def dot_binary(vec, bin_arr):
return np.apply_along_axis(
lambda x: np.sum(vec[x]) - np.sum(vec[~x]),
1,
bin_arr
)
The function dot_binary for each binary vector from the bin_arr will sum the values from positions of vec for which given binary vector is True and subtract the sum of values from positions of vec where the binary vector is False.
In principle this could speed up computation - we just sum values instead of doing bunch of multiplications. In addition our hash vectors will use up less memory.
The end
I hope you enjoyed reading the article. If you are interested in learning more about LSH or data mining in general I encourage you to check out the Mining of Massive Datasets free book. I used it when writing this post. Check also the blog for updates. I intend to write more about LSH in the future. If you would like to contact me send an email to: tostr.pl [~at~] gmail.com